Notice: This Wiki is now read only and edits are no longer possible. Please see: https://gitlab.eclipse.org/eclipsefdn/helpdesk/-/wikis/Wiki-shutdown-plan for the plan.
Configuring a Project (ELUG)
Contents
- 1 Configuring Common Project Options
- 2 Configuring Project Save Location
- 3 Configuring Project Classpath
- 4 Configuring Method or Direct Field Access at the Project Level
- 5 Configuring Default Descriptor Advanced Properties
- 6 Configuring Existence Checking at the Project Level
- 7 Configuring Project Deployment XML Options
- 8 Configuring Model Java Source Code Options
- 9 Configuring Cache Type and Size at the Project Level
- 10 Configuring Cache Isolation at the Project Level
- 11 Configuring Cache Coordination Change Propagation at the Project Level
- 12 Configuring Cache Expiration at the Project Level
- 13 Configuring Project Comments
This section describes how to configure EclipseLink project options common to two or more project types.
This table lists the types of EclipseLink projects that you can configure and provides a cross-reference to the type-specific chapter that lists the configurable options supported by that type.
| If you are creating... | See also... |
|---|---|
|
Relational Projects |
|
|
EIS Projects |
|
|
XML Projects |
The Common Project Options table lists the configurable options shared by two or more EclipseLink project types.
For more information, see the following:
Configuring Common Project Options
This table lists the configurable options shared by two or more EclipseLink project types. In addition to the configurable options described here, you must also configure the options described for the specific EclipseLink project types (see EclipseLink Project Types), as shown in the Configuring EclipseLink Projects table.
| Option to Configure | EclipseLink Workbench | Java |
|---|---|---|
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
Configuring Project Save Location
You can configure a project save location only when using Workbench.
This table summarizes which projects support a project save location.
| Descriptor | Using the Workbench |
Using Java |
|---|---|---|
|
Relational Projects |
|
|
|
EIS Projects |
|
|
|
XML Projects |
|
|
How to Configure Project Save Location Using Workbench
The Project Save Location field on the project's General tab is for display only. This field shows the full directory path for the project. All relative locations used in the project are based on this location.
General Tab, Project Save Location

To select a new location, right-click on the project in the Navigator and select Save As from the context menu. See How to Save Projects for more information.
Configuring Project Classpath
The EclipseLink project uses a classpath – a set of directories, JAR files, and ZIP files – when importing Java classes and defining object types.
This table summarizes which projects support project classpath configuration.
| Descriptor | Using the Workbench |
Using Java |
|---|---|---|
|
Relational Projects |
|
|
|
EIS Projects |
|
|
|
XML Projects |
|
|
Do not include JDBC drivers or other elements required to access the data source in the project classpath. Use the setenv file to specify these application-level settings (see Configuring the Workbench Environment).
After you configure the project classpath, you can use Workbench to import classes into your project (see How to Import and Update Classes).
How to Configure Project Classpath Using Workbench
To specify the project classpath information, use this procedure:
- Select the project object in the Navigator.
- Click the General tab in the Editor. The General tab appears.
General Tab, Classpath Options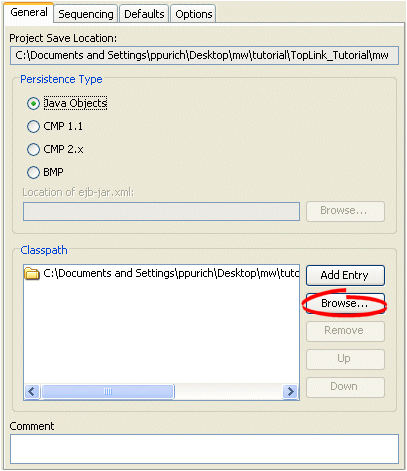

To add a new classpath entry, click Add Entry or Browse and select the directory, .jar file, or .zip file for this project. To create a relative classpath, select an entry and edit the path, as necessary. The path will be relative to the Project Save Location.
To remove a classpath entry, select the entry and click Remove.
To change the order of the entries, select the entry and click Up or Down.
Configuring Method or Direct Field Access at the Project Level
By default, when EclipseLink performs a persistence operation, it accesses the persistent attributes of an object directly: this is known as direct field access. Alternatively, you can configure EclipseLink to access persistent attributes using accessor methods of the object: this is known as method access.
We recommend using field access for mappings. Not only is it more efficient, but using method access may cause issues if the method produces unexpected side-effects.
This table summarizes which projects support mapped field access configuration.
| Descriptor | Using the Workbench |
Using Java |
|---|---|---|
|
Relational Projects |
|
|
|
EIS Projects |
|
|
|
XML Projects |
|
|
This section describes configuring mapped field access at the project level: by default, this configuration applies to all descriptors and their mappings.
|
Note: If you change the access default, existing mappings retain their current access settings, but new mappings will be created with the new default. |
You can also configure mapped field access at the mapping level to override this project-level configuration on a mapping-by-mapping basis. For more information, see Configuring Method or Direct Field Accessing at the Mapping Level.
If you enable change tracking on a property (for example, you decorate method getPhone with @ChangeTracking) and you access the field (phone) directly, note that EclipseLink does not detect the change. For more information, see Using Method and Direct Field Access.
How to Configure Method or Direct Field Access at the Project Level Using Workbench
To specify the field access method information, use this procedure:
- Select the project object in the Navigator.
- Select the Defaults tab in the Editor. The Defaults tab appears.
Defaults Tab, Field Accessing Options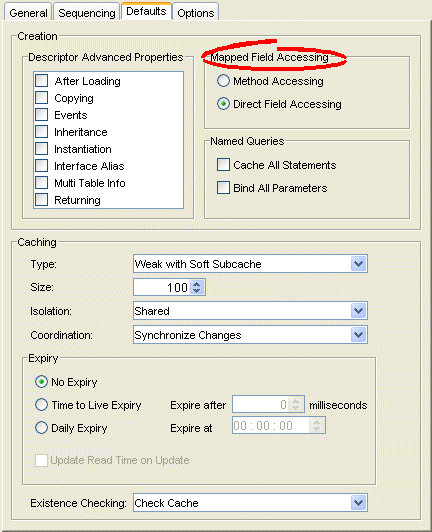
- Complete the Mapped Field Accessing options.

Configuring Default Descriptor Advanced Properties
You can configure default descriptor advanced properties when using the Workbench.
By default, Workbench displays a subset of features for each descriptor type. You can modify this subset so that descriptors include additional advanced properties by default.
You can also select specific advanced properties for individual descriptors (see Configuring a Descriptor).
This table summarizes which projects support default descriptor advanced property configuration.
| Descriptor | Using the Workbench |
Using Java |
|---|---|---|
|
Relational Projects |
|
|
|
EIS Projects |
|
|
|
XML Projects |
|
|
How to Configure Default Descriptor Advanced Properties Using Workbench
To specify the default advanced properties for newly created descriptors in your project, use this procedure:
- Select the project object in the Navigator.
- Select the Defaults tab in the Editor. The Defaults tab appears.
Defaults Tab, Descriptor Advanced Properties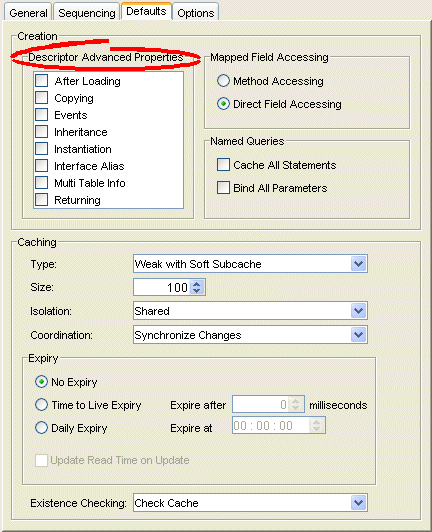

Select which Descriptor Advanced Properties to add to newly created descriptors. The list of advanced properties will vary, depending on the project type.
See Also
Configuring Existence Checking at the Project Level
When EclipseLink writes an object to the database, it runs an existence check to determine whether to perform an insert or an update operation.
By default, EclipseLink checks against the cache. We recommend that you use this default existence check option for most applications. Checking the database for existence can cause a performance bottleneck in your application.
This table summarizes which projects support existence checking configuration.
| Descriptor | Using the Workbench |
Using Java |
|---|---|---|
|
Relational Projects |
|
|
|
EIS Projects |
|
|
|
XML Projects |
|
|
By default, this configuration applies to all descriptors in a project. You can also configure existence checking at the descriptor level to override this project-level configuration on a descriptor-by-descriptor basis. For more information, see Configuring Cache Existence Checking at the Descriptor Level.
For more information see the following:
How to Configure Existence Checking at the Project Level Using Workbench
To specify the existence checking information, use this procedure:
- Select the project object in the Navigator.
- Select the Defaults tab in the Editor. The Defaults tab appears.
Defaults Tab, Existence Checking Options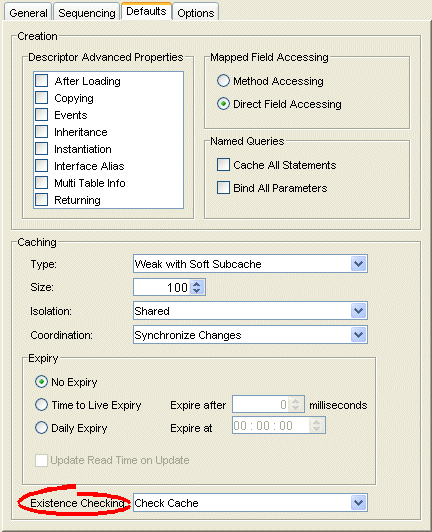
- Complete the Existence Checking options on the tab.

Use this table to enter data in following fields to specify the existence checking options for newly created descriptors:
| Field | Description |
|---|---|
| Check Cache |
Check the session cache. If the object is not in the cache, assume that the object does not exist (do an insert). If the object is in the cache, assume that the object exists (do an update). We recommend using this option for most applications. |
| Check Database |
If an object is not in the cache, query the database to determine if the object exists. If the object exists, do an update. Otherwise, do an insert. Selecting this option may negatively impact performance. For more information, see Using Check Database. |
| Assume Existence |
Always assume objects exist: always do an update (never do an insert). For more information, see Using Assume Existence. |
| Assume Nonexistence |
Always assume objects do not exist: always do an insert (never do an update). For more information, see Using Assume Nonexistence. |
Configuring Project Deployment XML Options
You can configure project deployment XML options when using Workbench.
Using Workbench, you can specify the default file names, class names, and directories, when exporting or generating deployment XML. Directories are relative to the project save location (see Configuring Project Save Location), and will contain folders for each generated package.
This table summarizes which projects support deployment XML options.
| Descriptor | Using the Workbench |
Using Java |
|---|---|---|
|
Relational Projects |
|
|
|
EIS Projects |
|
|
|
XML Projects |
|
|
How to Configure Project Deployment XML Options Using Workbench
To specify the default export options, use this procedure:
- Select the project object in the Navigator.
- Select the Options tab in the Editor. The Options tab appears.
Options Tab, Project Deployment XML Options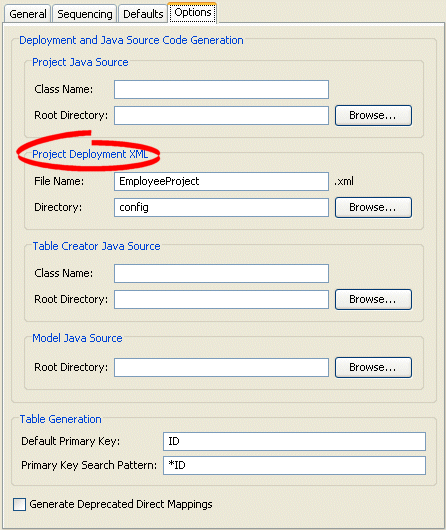
- Complete the fields on the [topicid:project.options.deployment Project Deployment XML options] on the tab.

Use this table to enter data in following fields to specify the default Project Deployment XML options:
| Field | Description |
|---|---|
| File Name | File name (such as project.xml) to use when generating project deployment XML. |
| Directory | Directory in which to save the generated deployment XML file. |
See Also
Configuring Model Java Source Code Options
You can configure model java source code options when using the Workbench.
Using Workbench, you can specify the default file names, class names, and directories, when exporting or generating Java source code for your domain objects. Directories are relative to the project save location (see Configuring Project Save Location), and will contain folders for each generated package.
This table summarizes which projects support model Java source code options.
Project Support for Model Java Source Options
| Descriptor | Using the Workbench |
Using Java |
|---|---|---|
|
Relational Projects |
|
|
|
EIS Projects |
|
|
|
XML Projects |
|
|
How to Configure Model Java Source Code Options Using Workbench
To specify the default export options, use this procedure:
- Select the project object in the Navigator.
- Select the Options tab in the Editor. The Options tab appears.
Options Tab, Model Java Source options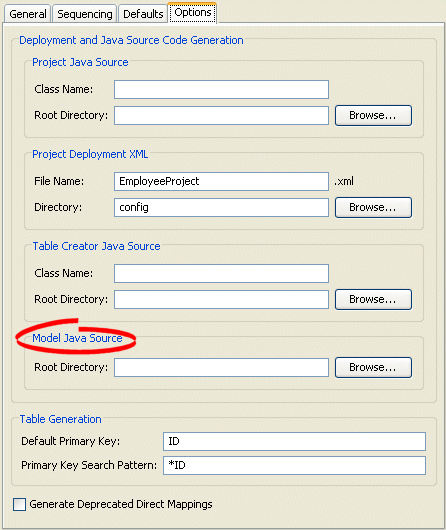
- Complete the fields on the Model Java Source options on the tab.
- Specify the project root directory to which Workbench generates model Java source files. For more information, see Generating Java Code for Descriptors.

See Also
Configuring Cache Type and Size at the Project Level
The EclipseLink cache is an in-memory repository that stores recently read or written objects based on class and primary key values. EclipseLink uses the cache to achieve the following:
- improve performance by holding recently read or written objects and accessing them in-memory to minimize database access;
- manage locking and isolation level;
- manage object identity.
This table summarizes which projects support identity map configuration.
Project Support for Identity Map Configuration
| Descriptor | Using the Workbench |
Using Java |
|---|---|---|
|
Relational Projects |
|
|
|
EIS Projects |
|
|
|
XML Projects |
|
|
The cache options you configure at the project level apply globally to all descriptors. Use this section to define global cache options for an EclipseLink project.
You can override the project-level identity map configuration by defining identity map configuration at the descriptor level. For information on caching and defining identity map configuration for a specific descriptor, see Configuring Cache Type and Size at the Descriptor Level.
|
Note: When using Workbench, changing the project's default identity map does not affect descriptors that already exist in the project; only newly added descriptors ar affected. |
For detailed information on caching and object identity, and the recommended settings to maximize EclipseLink performance, see to Cache Type and Object Identity.
For more information about the cache, see Introduction to Cache.
How to Configure Cache Type and Size at the Project Level Using Workbench
To specify the cache identity map, use this procedure:
- Select the project object in the Navigator.
- Select the Defaults tab in the Editor. The Defaults tab appears.
Defaults Tab, Cache Identity Map Options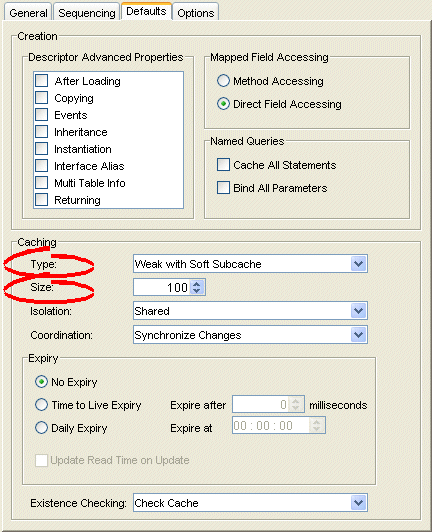
- Complete the Caching options on the tab.

Use this table to enter data in each of the following fields to specify the caching options:
| Field | Description |
|---|---|
| Type |
Use the Type list to choose the identity map as follows:
For more information, see Cache Type and Object Identity. Changing the project's default identity map does not affect descriptors that already exist in the project. |
| Size |
Specify the size of the cache as follows:
|
How to Configure Cache Type and Size at the Project Level Using Java
Use one of the following ClassDescriptor methods to configure the descriptor to use the appropriate type of identity map:
- useFullIdentitMap
- useWeakIdentitMap
- useSoftIdentitMap
- useSoftCacheWeakIdentitMap
- useHardCacheWeakIdentityMap
- useNoIdentityMap
Use the ClassDescriptor method setIdentityMapSize to configure the size of the identity map.
Configuring Cache Isolation at the Project Level
If you plan to use isolated sessions (see Cache Isolation), you must configure descriptors as isolated for any object that you want confined to an isolated session cache.
Configuring a descriptor to be isolated means that EclipseLink will not store the object in the shared session cache and the object will not be shared across client sessions. This means that each client will have their own object read directly from the database. Objects in an isolated client session cache can reference objects in their parent server session's shared session cache, but no objects in the shared session cache can reference objects in an isolated client session cache. Isolation is required when using Oracle Database Virtual Private Database (VPD) support or database user-based read security. Isolation can also be used if caching is not desired across client sessions.
This table summarizes which projects support cache isolation configuration.
| Descriptor | Using the Workbench |
Using Java |
|---|---|---|
|
Relational Projects |
|
|
|
EIS Projects |
|
|
|
XML Projects |
|
|
The cache isolation options you configure at the project level apply globally to all descriptors. Use this section to define global options for an EclipseLink project.
You can override the project-level configuration by defining cache isolation options at the descriptor level. For information, see Configuring Cache Isolation at the Descriptor Level.
|
Note: When using Workbench, changing the project's default cache isolation option does not affect descriptors that already exist in the project; only newly added descriptors ar affected. |
How to Configure Cache Isolation at the Project Level Using Workbench
To specify the cache isolation options, use this procedure:
- Select the project object in the Navigator.
- Select the Defaults tab in the Editor. The Defaults tab appears.
Defaults Tab, Cache Isolation Options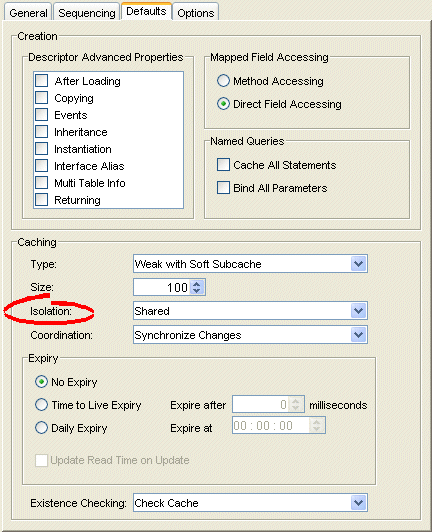
- Complete the Isolation option on the tab. Use the Isolation list to choose one of the following:
- Isolated – if you want all objects confined to an isolated client session cache. For more information, see Cache Isolation.
- Shared – if you want all objects visible in the shared session cache (default).

Configuring Cache Coordination Change Propagation at the Project Level
If you plan to use a coordinated cache (see Cache Coordination), you can configure how and under what conditions a coordinated cache propagates changes.
This table summarizes which projects support cache coordination change propagation configuration.
Project Support for Cache Coordination Change Propagation Configuration
| Descriptor | Using the Workbench |
Using Java |
|---|---|---|
|
Relational Projects |
|
|
|
EIS Projects |
|
|
|
XML Projects |
|
|
The cache coordination change propagation options you configure at the project level apply globally to all descriptors. Use this section to define global options for an EclipseLink project.
You can override the project-level configuration by defining cache coordination change propagation options at the descriptor level. For information, see Configuring Cache Coordination Change Propagation at the Descriptor Level.
To complete your coordinated cache configuration, see Configuring a Coordinated Cache.
|
Note: When using Workbench, changing the project's default cache coordination change propagation option does not affect descriptors that already exist in the project; only newly added descriptors ar affected. |
How to Configure Cache Coordination Change Propagation at the Project Level Using Workbench
To specify the coordinated cache change propagation options, use this procedure:
- Select the project object in the Navigator.
- Select the Defaults tab in the Editor. The Defaults tab appears.
Defaults Tab, Coordination Options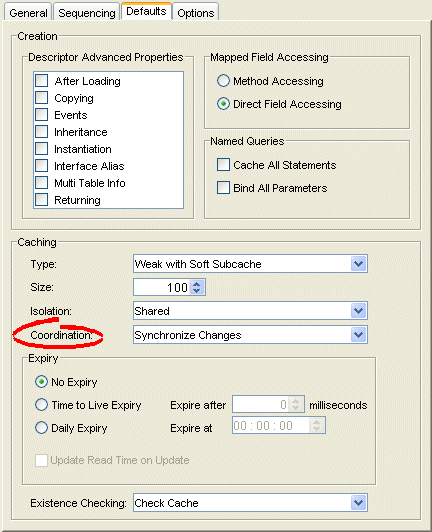
- Complete the Coordination option] on the tab.

Use the following information to enter data in the Coordination field:
| Coordination Option | Description | When to Use |
|---|---|---|
| None | For both existing and new instances, do not propagate a change notification. | Infrequently read or changed objects. |
| Synchronize Changes |
For an existing instance, propagate a change notification that contains each changed attribute. For a new instance, propagate an object creation (along with all the new instance's attributes) only if the new instance is related to other existing objects that are also configured with this change propagation option. |
Frequently read or changed objects that contain few attributes or in cases where only a few attributes are frequently changed. Objects that have many or complex relationships. |
| Synchronize Changes and New Objects |
For an existing instance, propagate a change notification that contains each changed attribute. For a new instance, propagate an object creation (along with all the new instance's attributes). |
Frequently read or changed objects that contain few attributes or in cases where only a few attributes are frequently changed. Objects that have few or simple relationships. |
| Invalidate Changed Objects |
For an existing instance, propagate an object invalidation that marks the object as invalid in all other sessions. This tells other sessions that they must update their cache from the data source the next time this object is read. For a new instance, no change notification is propagated. |
Frequently read or changed objects that contain many attributes in cases where many of the attributes are frequently changed. |
Configuring Cache Expiration at the Project Level
By default, objects remain in the cache until they are explicitly deleted (see Deleting Objects) or garbage-collected when using a weak identity map (see Configuring Cache Type and Size at the Project Level). Alternatively, you can configure an object with a CacheInvalidationPolicy that lets you specify, either automatically or manually, that an object is invalid: when any query attempts to read an invalid object, EclipseLink will go to the data source for the most up-to-date version of that object and update the cache with this information.
Using cache invalidation ensures that your application does not use stale data. It provides a better performing alternative to refreshing (see Configuring Cache Refreshing).
This table summarizes which projects support cache invalidation configuration.
| Descriptor | Using the Workbench |
Using Java |
|---|---|---|
|
Relational Projects |
|
|
|
EIS Projects |
|
|
|
XML Projects |
|
|
The cache invalidation options you configure at the project level apply globally to all descriptors. Use this section to define global cache invalidation options for an EclipseLink project.
You can override the project-level cache invalidation configuration by defining cache invalidation at the descriptor (see Configuring Cache Expiration at the Descriptor Level) or query level (see How to Configure Cache Expiration at the Query Level).
You can customize how EclipseLink communicates the fact that an object has been declared invalid to improve efficiency if you are using a coordinated cache. For more information, see Configuring Cache Coordination Change Propagation at the Descriptor Level.
|
Note: When using Workbench, changing the project's default cache invalidation does not affect descriptors that already exist in the project; only newly added descriptors are affected. |
For more information, see Cache Invalidation.
How to Configure Cache Expiration at the Project Level Using Workbench
To specify the cache expiration options for the project, use this procedure:
- Select the project object in the Navigator.
- Select the Defaults tab in the Editor. The Defaults tab appears.
Defaults Tab, Cache Expiry Options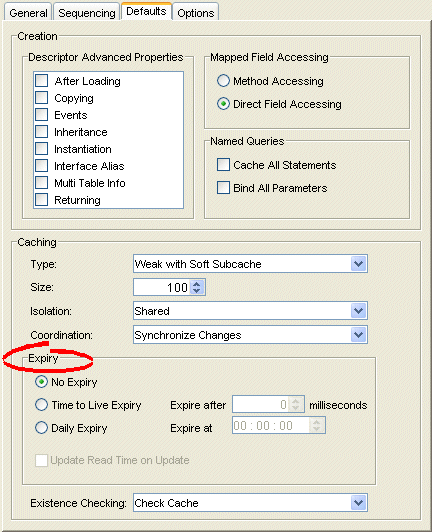
- Complete the Cache Expiry options on the tab.

Use this table to enter data in the following fields on this tab:
| Field | Description |
|---|---|
| No Expiry | Specify that objects in the cache do not expire. |
| Time to Live Expiry | Specify that objects in the cache will expire after a specified amount of time. Use the Expire After field to indicate the time (in milliseconds) after which the objects will expire. |
| Daily Expiry | Specify that objects in the cache will expire at a specific time each day. Use the Expire At field to indicate the exact time to the second (using a 24-hour clock) at which the objects will expire. |
| Update Read Time on Update | Specify if the expiry time should be reset after updating an object. |
|
Note: These options apply to all descriptors in a project. See Configuring Cache Expiration at the Descriptor Level for information on configuring descriptor-specific options. |
Configuring Project Comments
You can define a free-form textual comment for each project. You can use these comments however you whish: for example, to record important project implementation details such as the purpose or importance of a project.
In a Workbench project, the comments are stored in the EclipseLink deployment XML file. There is no Java API for this feature.
This table summarizes which projects support this option.
| Project Type | Using the Workbench |
Using Java |
|---|---|---|
|
Relational Projects |
|
|
|
EIS Projects |
|
|
|
XML Projects |
|
|
How to Configure Project Comments Using Workbench
To specify a comment for the project, use this procedure:
- Select the project object in the Navigator.
- Select the General tab in the Editor. The General tab appears.
General Tab, Comments Options
- Enter descriptive text information in the Comment field.
