Notice: this Wiki will be going read only early in 2024 and edits will no longer be possible. Please see: https://gitlab.eclipse.org/eclipsefdn/helpdesk/-/wikis/Wiki-shutdown-plan for the plan.
Eclipse 4diacWiki/Development/Model-based Testing for IEC 61499 Function Blocks
Overview page of GSoC 2022 Project
The aim of this project is to provide better tool support for executing test cases with an interpreter, in order to improve the usability of the IDE.
Contents
Project Goals
Eclipse 4diac provides an open source environment for users who wish to design an automation solution for buildings, electrical grids, or factories. A key goal of the project is to support engineers with sophisticated tool support. The proposed project permits a novel model-based testing workflow for engineers that takes optimal use of existing models. This project required an analysis in the state of the art of model-based testing in order to provide optimal benefit to the users of 4diac IDE. As a result, an initial literature review revealed potential implementation techniques that can be compared. Based on this analysis, a prototype was implemented together with the respective user interface.
Milestones
Implementation Plan and Testing Techniques
Testing Function Blocks is currently a manual Process and test data is entered by hand by domain experts. Test data include events and data values.
Meaningful test data should be provided based on the modeled information to increase coverage.
Test creation strategies to investigate:
- fully random
- based on partial user input
- based on the implementation (branch coverage)
- using genetic algorithms (mutation-based and/or crossover between children with high fitness)
- for data values -> e.g., bell curve for physical values
- for data values -> upper and lower limits
A dialogue for user interaction (or buttons integrated in the current UI) will be needed to trigger the processes.
Data should be
- accessible via an API to other plug-ins (plug-ins can request test data)
- stored in a file for efficiency/performance (allow saving test sequences/exporting test sequences)
Implementation Steps
Reducing Code Duplication
The first two work packages address the aforementioned problems of the project infrastructure. An FB interpreter allows executing the model directly without generating code or even saving the model to a file. At the beginning of the project, duplicated code was identified: Executing sequences requires similar code as running tests. This was addressed by introducing model factories for the common objects that are needed by the interpreter (e.g., runtimes or event occurrences). The cleanup also revealed minor inconsistencies in different parts of the interpreter that could be fixed (Bug 580498). The factories with a convenient API will help users in the future to apply the interpreter more easily in new use cases.
This work was split into several commits. New factories are available for event occurrences and runtimes (195030) and transactions (194989, 195043). Additionally, a factory allows creating elements of a Service Sequence via convenience methods with useful default values (195388).
Finally, the interpreter used to work only with several kinds of FBs. Where possible, the abstraction was increased to work with any kind of FB (e.g., Commit 195030 and 195381). The factories were adopted also in the code for testing FBs (195381).
Generic code from the interpreter test cases is applicable not only in the context of unit tests, but can be reused across interpreter execution (Bug 580133). These functions were extracted into separate methods and sorted according to topics. Where possible, functions were generalized to work with any kind of FB. (195166)
Dependency Resolution
The Service Sequence Editor had a dependency to the test.fb.interpreter plugin because it used utility methods (Bug 580624). This dependency to a test plugin not only violated the architecture of 4diac IDE code, but also hindered further code reuse. It was thus resolved. To avoid code duplication, methods had to be extracted from the AbstractInterpreterTest into fitting helper classes: Commit 195384
Model Interpreter
The model-based testing framework builds on the interpreter for both individual FBs and FB networks. This interpreter allows to execute such model elements without using a runtime - and thus facilitates integration of tests into test pipelines. The interpreter for FB networks is still an early prototype (Bug 579702). In the process of integrating this interpreter into the framework, some improvements were provided to the existing code. (Commit 195357, Commit 195358 , Commit 195510, Commit 195565)
Prototype for Test data generation
Meaningful test data has to utilize the model information from the IEC 61499 model. For instance, the available input event pins define possible event triggers. Test creation strategies that were investigated include fully random sequences and sequences that are optimized by a genetic algorithm.
a) Random
As a first step towards Bug 580133, random test data was generated and used for model-based testing. First of all, a random event sequence is required which contains (multiplicities of) input events from the FB type. For instance, for a counter FB type, a sequence could be R -> R -> R -> CU -> CU. Random events can be found by getting a random index from the list of input events, cf. Commit 194988
For a sequence, random input data should also be created. For this, the data associated with an event (WITH-construct) has to be randomized. Data values that are fed to the interpreter need to follow the IEC 61131-3 standard, e.g., for integer values the prefix INT#0. Furthermore, the standard defines a wide range of data types, which do not match the ones available in the Java language (e.g., unsigned data types). Therefore, manual manipulation was necessary to ensure correct formatting on all random elements. Only those data types that are exactly defined in the standard were implemented, some are vendor-specific. Implemented data creation strategies were (1) fully random values from the whole range of the data type, (2) fully random values from a subrange of the data type, and (3) Gauss distributed values for a specified mean value and a specified standard deviation.
Commits 195031, 195417, 195892, 196189, and 195141.
b) Genetic algorithms A genetic algorithm mimics the process of evolution in nature. For a single or a set of parent elements, a number of children is created using mutation and recombination techniques. Mutation means that one element is randomly altered, e.g., a data value could be changed. Recombination means that a child is created by combining two parts from different parents. Finally, a selection mechanism has to select the n fittest elements from the population (parents and children). These are used for the next iteration or the best solution is returned as a result.
Genetic algorithms are suitable for optimization. Based on a reasonable input event sequence (e.g. randomly generated), the genetic algorithm optimizes for a fitness function. This provides sequences that are well-adapted to the specific FB (Bug 580585).
Relevant mutations for test input sequences are:
- using a different input event at position i of the sequence
- adding an input event to the sequence (at the end)
- exchanging the position of two input events at position i and i+1
- deleting an input event from the sequence
- changing an associated data value for an event
A number of recombination strategies are possible for event sequences. We implemented the strategy to take a cut-out of length a from one sequence A and replace cut-out b from another sequence B. The cut-out parts do not have to be of equal length.
As part of this implementation, various strategies for selection were evaluated. Test sequences that are well-adapted to a Function Block often offer more output events than test sequences, which use input events that do not make sense in the context of the test scenario. Therefore, a higher ratio between output events and input events was rewarded. Test sequences with 0 length are not valid and are therefore treated with a strong malus. For the evaluation, a test function block was created. Another idea of a fitness function was to evaluate the coverage, e.g., the number of branches that were taken in the state diagram. However, the model-based testing framework of 4diac IDE aims at an implementation-agnostic test generation that is not limited to Basic FBs with a state diagrams. As a result, this approach was dismissed. A further idea for rewards includes a bonus for changing data values.
Test Data Generation With a User Interface
Recording tests manually required entering input events in a message box. Test execution was already possible before this project, but it altered the type definition, which is of course unwanted. Hence, the execution was adapted to work with a copy of the currently opened FBType (Bug 580611, 195347)
The test data generation was integrated into a dialogue for recording sequences. Test sequences consist of a series of input events. For instance, for a Function Block with the event inputs INIT, START, and STOP, a random sequence of length 5 could look as follows: STOP - START - START - INIT - STOP For Basic Function Blocks, also the start state can be selected. This allows, for example, running test sequences that start from an error detection state. Such states can be hard to reach with input combinations, for instance, when a timeout detection is involved.
In the example sequence, it is clear that sending a STOP event before a START event is not a realistic scenario. While such sequences are valuable test cases as well, users may want to specify a certain startup sequence for their test case as in the following example: INIT - START - …. (x random events) This is possible by specifying the input events INIT;START, specifying the number of random events as count and selecting the checkbox random.
The following screenshot shows the current user interface, accessible in 4diac IDE via Source/Record Service Sequence (pre-requisite: a Service Sequence is selected).
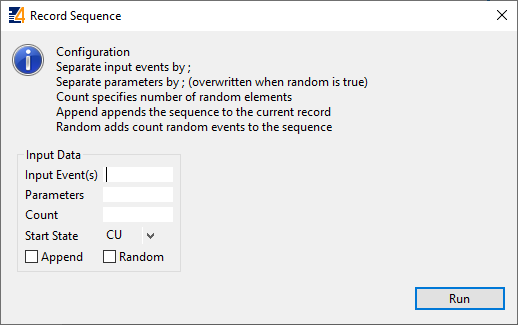

Commits 195098, 195143, 195322
Trace Comparison
Bug 580548: An initial code for comparing interpreter results with Service models is available (mostly in the AbstractInterpreterTest).
It had to be expanded to - allow checking between INT#5 and 5 - allow forbidden/possible/mandatory traces - be more defensive against incorrect user input
Commit 195144
Final Report (Summary)
4diac IDE supports developing Function Blocks (FBs) for the library. This includes testing and debugging these blocks. In this Google Summer of Code-project, the infrastructure for testing FBs directly in the IDE was improved and a prototype for generating FB test sequences was created (including a user interface). As common for projects of this scope, some problems in the existing code base were only revealed during the work of the project. Therefore, they had to be fixed in addition to working on the model-based testing framework. This particularly addresses the interpreter, which my framework heavily builds upon. As a result, some of the topics (e.g. user interface for genetic algorithms) could not be researched in-depth, yet a working prototype is available as part of Eclipse 4diac. All the deliverables described in the project proposal were merged into the 4diac IDE repository. Especially for genetic algorithms, further research is required to find optimal test scenarios.
A list of all my commits is available under the following link: Gerrit